Concepts
In order to use FactCast effectively it is necessary to have an overview of the concepts and to understand
how FactCast might differ from other solutions you are already familiar with. So let’s take a look at the basics:
Write (publish)
With FactCast you can publish Facts which will be written into a log. You can publish a single Fact as well as a
list of Facts atomically (all-or-none).
With optimistic locking you can use conditional publishing, which is based upon aggregates that do not change during the
lifecycle of the lock (see optimistic locking).
Read (subscribe)
In order to receive Facts you have to subscribe to FactCast with a subscription request. This is where FactCast
significantly differs from other solutions because the subscription request contains the full specification of what
events to receive. This means that no server-side administration is needed, nor any prior knowledge about the streams
where to publish the Facts into.
TODO see SubscriptionRequest
In addition to the specification of events to read, the SubscriptionRequest also specifies the events to skip (e.g.
due to previous consumption). The request also defines how to deal with Facts being published in the future.
Note that Facts are always guaranteed to be sent in the order they were published.
The three usual subscription models and their corresponding use cases are:
| Subscription Type | Description |
|---|
| Follow | This covers the 80% of the use cases. Here the consumer catches up with Facts from the past and also receives Facts in the future as they are published.On subscription the consumer sends the id of the last event processed and gets every Fact that matches the specification and has been published after this last known Fact. |
| Catchup | This subscription catches up with past events but does not receive any new Facts in the future. A usual use case for this subscription is a write model that needs to collect all kinds of information about a specific aggregate in order to validate or to reject an incoming command. |
| Ephemeral | The consumer does not catch up with past events, but receives matching Facts in the future.A possible use case is e.g. cache invalidation. Not suitable for read models. |
All these subscription types rely on a streaming transport which uses (at the time of writing) GRPC.
Read (fetch)
In some situations the bandwidth of the consumption has to be reduced. This can happen if either there are too many
consumers interested in the same Fact or consumers keep receiving the same Facts (e.g. catchup subscriptions without
snapshotting). Pushing only ‘ids’ (or URLs) instead of complete Facts can improve the performance. Depending on
the protocol being used HTTP-Proxies or local caches can also be applied for further performance enhancement.
1 - The Anatomy of a Fact
Facts
FactCast is centered around Facts. We say Facts instead of Events, because Event has become a blurry term that could mean any number of things from a simple onWhatNot() call handled by an Event-Loop to a LegalContractCreated with any flavor of semantics.
We decided to use the term Fact over Domain-Event because we want to highlight the notion of an Event being an immutable thing that, once it is published, became an observable Fact.
Obviously, a Fact is history and cannot be changed, after it happened. This is one of the cornerstones of EventSourcing and provides us with Facts being immutable, which plays an important role when it comes to caching.
Facts consist of two JSON documents: Header and Payload.
consists of:
- a required Fact-Id ‘id’ of type UUID
- a required namespace ’ns’ of type String
- an optional set of aggregateIds ‘aggId’ of type array of UUIDs
- an optional (but mostly used) Fact-Type ’type’ of type String
- an optional Object ‘meta’ containing any number of key-value pairs, where the values are Strings
- any additional information you want to put in a Fact Header
JSON-Schema:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"definitions": {},
"id": "http://docs.factcast.org/example/fact.json",
"properties": {
"id": {
"id": "/properties/id",
"type": "string",
"pattern": "^[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}$"
},
"aggIds": {
"id": "/properties/aggIds",
"type": "array",
"items": {
"id": "/properties/aggIds/items",
"type": "string",
"pattern": "^[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}$"
}
},
"ns": {
"id": "/properties/ns",
"type": "string"
},
"type": {
"id": "/properties/type",
"type": "string"
},
"meta": {
"id": "/properties/meta",
"type": "object",
"additionalProperties": {
"type": "string",
"description": "Some string values"
}
}
},
"type": "object",
"additionalProperties": {
"type": "object"
},
"required": ["id", "ns"]
}
The Meta-Data Object is optional and consist of key:value pairs. The reason for it is that implementations can filter facts on certain attributes efficiently (without indexing the whole Fact payload).
When a fact is read from FactCast, it is guaranteed to have two field set in the Meta-Data object of the header:
| Attribute | Type | Semantics |
|---|
| _ser | long / int64 | unique serial number for the fact, that determines a before/after relationship between facts |
| _ts | long / int64 | timestamp in milliseconds, when this fact was published to factcast. |
As you can see, all meta-data attributes prefixed with “_” are supposed to be server created, so please do not use an “_” prefix yourself.
The Payload
The payload has no constraints other than being a valid JSON document.
please, see GRPC docs for further details.
2 - Fact Specification
When consumers subscribe to a Stream of Events, it has to express, which Events he wants to receive. The more precise this can be done, the less resources like bandwidth, CPU-Time etc. are wasted.
As discussed here, there is more than one way to do it. We decided to go for just-in-time filtering in FactCast. Here is why:
The problem with FactStream-IDs
EventStore – which is a wonderful product by the way - is a good example of Filtering/Transforming/Meshing of Events ahead of time. You inject JavaScript Code as a so-called ‘Projection’ into the Server, that builds a new Stream of Events by picking, and maybe even transforming Events into a new Stream with a particular ID. A consumer then subscribes to that particular EventsStream, thus gets exactly what he expects.
While that is a wonderful concept, that guarantees very good performance when actually streaming, it highlights a little organizational difficulty: Where to put this code? This is a problem similar to automatically maintaining Schemas in a relational Database, tackled by Liquibase et al.
- How can an application know if a matching Projection already exists and is what is expected?
- How to coordinate the creation of relevant Projections in the face of horizontal scalability (many instances of you application coming to live at roughly the same point in time) and
- what about canary releases with changing (probably not changing, but replacing) Projections?
While these Problems are certainly solvable, we went for an easier, but certainly not as fast solution:
Just In Time Filtering
According to a list of Fact-Specifications, the matching Facts are queried from the database just in time. When querying lots of Facts (like for instance following from scratch), we use a GIN Index to find the matching facts in the Database easily. When reaching the end of the Stream, the index is no longer used, as scanning the ‘few’ new rows that were inserted in a limited time-frame is easier than iterating the index.
In order to match with a high selectivity, this query uses some (in parts optional, but defined) Attributes from the JSON-Header of a Fact. In many cases, this filtering is already sufficient to reduce the number of misses (Facts that are sent to the consumer, but discarded there) to either zero or something very near.
Specification
In order to efficiently select matching Facts from the Database, a consumer should provide precise information about which Facts match, and which do not.
In order to do that, a list of FactSpec-Objects is transferred on subscription. Any Fact that matches ANY ONE of the specifications, will be sent to the consumer.
FactSpec-Objects must define a ns attribute. The rest is actually optional:
| Attribute | Type | Semantics |
|---|
| ns | String | Namespace |
| type | String | Type of Fact |
| aggId | UUID | Aggregate-ID |
| meta | JSON Object with String Properties | A list of String key-value pairs (Tags) to match |
| metaKeyExists | JSON Object with Boolean Properties | A list of keys that MUST exist if the value is true, or MUST NOT exist if value is false |
| jsFilterScript | String (JavaScript) | Scripted Predicate, see below |
Of course, all the requirements defined in a FactSpec have to be met for a Fact to be matched.
Post-Query Filtering / Scripted Predicates
As discussed here, there are situations, where these tagging/categorizing means are not enough, because you just do not have this information in the header, or you need some more fine-grained control like Range-expressions etc.
This is where scripted Predicates come in.
Additionally to the above Attribute Specification a matching Fact must adhere to, you can define a JavaScript Predicate, that decides, if the Fact should be matching or not. In order to use this feature, the consumer provides a script as part of the specification, that implements a predicate function being passed the header and the payload of the Event in question, and is expected to return true if it should be sent to the consumer.
Example:
function (header,payload) {
return
header.myExtraAttribute.userLevel > 5
&&
payload.userBeingFollowed.countryCode = 'DE';
}
Please be aware, that using this feature increases load on the FactCast Server considerably. Also make sure, that the rest of the FactSpec is detailed enough to prefilter non-matching Facts at the database-level.
To say it again: ONLY MATCH IN A SCRIPT, WHAT CANNOT BE FILTERED ON OTHERWISE
3 - FactStream Design
Fact Stream design
If you are familiar with other products that store Facts, you might be familiar with the concept of a Fact-Stream. In
most solutions, the consumer subscribes to particular stream of Facts and then picks those of interest for him.
FactStream per Aggregate
A simple example would be to have all Facts regarding a particular Aggregate Root in one FactStream, identified by the
Aggregate’s id. Something along these lines:
User-1234
UserCreated
UserNameChanged
UserPasswordResetRequested
UserPasswordReset
While this kind of Stream design makes it trivial to find all the Facts that have to be aggregated to reconstruct the
state of User(id=1234), you are not done, yet.
Facts that are not picked by Aggregate-Id
Let’s just say, we want to create a report on how many UserPasswordReset Facts there are per Month. Here we are facing
the problem, that (well after publishing the Fact), we need to pick only those UserPasswordReset from the Store,
regardless of any Aggregate relation.
Here we see, that relying only on ahead of time tagging and categorizing of Facts would break our necks. If we don’t
have a way to express out interest in particular Facts, maybe based on criteria, we come up with a year after publishing
the Facts, FactSourcing either looses its point or at least get frustratingly inefficient, because you’d need to iterate
any Fact there is, and filter on the consumer side.
Here we are faced with the necessity of Store-Side filtering of FactStreams.
Facts that have an effect on multiple Aggregates
What about Facts, that have impact to more than one Aggregates?
User-1234
UserCreated
UserFollowedUser
Here the second Fact obviously has impact on both the following, as well as the user being followed.
Bad Practice: Splitting Facts
While we have seen people split the semantically unique Fact UserFollowedUser into UserFollowedUser and
UserWasFollowed, we don’t believe in that approach, as it creates lots of Facts that are only loosely connected to
the original fact, that some user clicked “follow” on some other users profile.
More formally: by doing that, the publisher has to know about the domain model in order to correctly slice and direct
Facts to the Aggregates. Not at all a good solution, as Facts last forever, while Domain Models do change over time,
if you want them to, or not.
Include Facts in different Streams
Certainly better is the idea of publishing one UserFollowedUser, and make both Aggregates (The user following and the
one being followed) consume this Fact. For that reason, some solutions (like FactStore, for instance) give you the
opportunity to pick that Fact and place it into both Fact Streams, the originators and the targeted users.
In order to do that, you inject JavaScript Projection code into the FactStore, that builds a particular FactStream
directed to the consumer.
Possible pitfalls
Consider an Aggregate User (pseudocode):
User {
UUID id
String name
}
and Facts like UserCreated (trivial, so we’re skipping it here), and UserDeleted that just has the id of the
user to delete.
This will lead to an Aggregate class User with handler methods similar to: (using Factus Syntax here for
brevity)
@Handler
void apply(UserCreated created) {
this.id = created.id;
this.name = created.name;
}
@Handler
void apply(UserDeleted deleted) {
this.deleted = true;
}
You can do this, because when asking for a FactStream for that Aggregate,
the facts will be filtered for those, that have a header with the array-attribute aggIds containing the id of the
user.
All fine until here.
But what happens, if you add another user reference to the UserDeleted Event?
UserDeleted {
UUID id // the one to actually delete
UUID deletedByUserId // the user that triggered the deletion
}
If the handlers stay unchanged, then (as the aggIds should contain all the aggregates involved)
one UserDeleted Fact would not only be handled by the Aggregate of the deleted user but also by
the Aggregate of the user that triggered the deletion, resulting in both being marked as deleted.
This is especially true if you use Event Objects that build the aggIds header attribute automatically.
So in this case, it’d be necessary, to ensure that the reason the handler method receives the fact/event is
actually the intended one:
@Handler
void apply(UserDeleted deleted) {
if (id.equals(deleted.id))
this.deleted = true;
// else skip processing
}
Conclusion
As a consumer, you need to be able to express, what Facts are of interest to you. While tagging/categorizing those Facts
might help when filtering, you cannot possibly rely on being able to predict all future needs when publishing a Fact.
The actual filtering of FactStreams according to the consumer’s needs should also probably be done within the Store, for
efficiency reasons. You don’t want to flood the network with Facts that end up being filtered out, if at all possible.
This requires a flexible way of expressing, what Facts you are interested in, ultimately leading to scripted
Predicates.
Filtering could be done either ahead of time (by emitting Facts into different Streams and creating new Streams whenever
a consumer’s need changes), or just-in-time, which might have some impact on performance.
Fact Specification
4 - Schema validation and Registry
Since version 0.2.0, FactCast can be configured to validate Facts before publishing them. In order to do that, FactCast
needs to have a Schema for the Namespace/Type/Version of a Fact, that is expected to live in a Schema-Registry. The
Schema Registry is a static website, that is referenced by the property ‘factcast.store.schemaRegistryUrl’. If no '
schemaRegistryUrl’ is provided, validation is skipped and FactCast behaves just like before.
Given, there is a SchemaRegistry configured, FactCast will (on startup, and regularly) fetch an index and crawl updated
information.
For that to work, the schema-registry must follow a certain structure and naming convention. To make validating and
building this static website easier and convenient, there is a
tool factcast-schema-cli you can use. It turns raw data files (Json-Schema,
markdown, example json payloads) into a nice, browsable website as well as generating the files needed for FactCast to
discover new schema on the fly.
An example can be
found here
which is generated from the module ‘factcast-examples/factcast-example-schema-registry/’
See the Properties-Section on how to configure this.
5 - Transformation
Stay compatible
When decoupling services via facts, it is vitally important, that the consuming party understands the facts it is interested in. Therefore, evolution is a challenge. As soon, as the publisher starts publishing a particular fact type in a (non-compatible) format, the consumer will break. This leads to complex deployment dependencies, that we tried to avoid in the first place.
In order to avoid this, the most important advice is:
make sure, new fact versions are always downwards compatible
and
make sure you tolerate unknown properties when processing facts
If there are only additions for instance in the new fact version, then the ’tolerant reader’ can kick in and ignore unknown properties. See Tolerant Reader
Sometimes however, you need to change a fact schema in terms of structure. We assume here, you use a Schema/Transformation registry, as this feature is disabled otherwise.
Downcast
In the above scenario, the publisher wants to start publishing facts with the updated structure (version 2) while the consumer that expects the agreed upon structure (version 1) should continue to work.
For this to work, there are three prerequisites:
- The publisher needs to communicate what version he wants to publish
This would not work otherwise, because we assume version 1 and version 2 to be incompatible, so the correct schema must be chosen for validation anyway.
In this case, it would be “version 2”.
- The consumer must express his expectation
When it subscribes on a particular fact type, it also needs to provide the version it expects (“version 1” here)
- A transformation code is available in the registry that can do the transformation if needed.
The Registry takes little javascript snippets, that can convert for instance a version 2 fact payload, into a version 1.
Factcast will build transformation chains if necessary (from 4-3, 3-2 and 2-1, in order to transform from version 4 to version 1). Every non-existent transformation is assumed compatible (so no transformation is necessary).
When necessary, you also can add a 4-1 transformation to the registry to do the transformation in one step, if needed. Beware though, you will not benefit much in terms of performance from this.
Transformation rules
- If there are many possible paths to transform from an origin version to a specific target version, the shortest always wins. If there are two equally long paths, the one that uses the bigger shortcut sooner wins.
- A consumer also can be able to handle different versions for a particular fact type. In this case – again – the shortest path wins. If there is a tie, the higher target version wins.
Upcast
Another use-case is that, over time, the publisher published 3 different versions of a particular fact type, and you (as a consumer) want to get rid of the compatibility code dealing with the older versions.
Same as downcast, just express your expectation by providing a version to your subscription, and factcast will transform all facts into this version using the necessary transformations from the registry.
While for downcast, missing transformations are considered compatible, upcasting will fail if there is no transformation code to the requested version.
In terms of transformation priorities: the same rules as in down-casting apply.
If transformation is not possible due to missing required code snippets in the registry or due to other errors, FactCast will throw an exception.
Caching
Obviously, transformation via javascript from a VM brings a considerable overhead. (Might be better with graal, which is not yet supported)
In order not to do unnecessary work, factcast will cache the transformation results, either in memory or persistently.
See the Properties-Section on how to configure this.
Note: Whenever a transformation is not possible, factcast will just throw an appropriate exception.
For an example, see the example registry
Remember that problems in the registry can cause errors at runtime in factcast, so that you should validate the syntactical correctness of it. This is where the cli tool will help.
6 - Blacklisting
In rare occasions it can happen that one or more facts were emitted that are broken in a way that makes it necessary to
remove them from the fact stream altogether. Events including or referencing malware might be an example.
Blacklisting provides a way to prevent single facts from being delivered to
any consumers, without the need to actually delete them from the history.
A word of caution
Please remember that removing or altering facts that already got emitted from the fact stream, no matter if through
deletion or blacklisting, should be avoided whenever it is possible as this contradicts the core principle in
event-sourcing that facts are immutable. Also remember that just blacklisting a fact won’t revert that consumers might
have processed and reacted to that fact already and removing it later might prevent reproducing the current state of the
system.If nevertheless you need to blacklist facts, there are two options:
The postgres blacklist (default)
Blocked fact IDs can be added to a table named “blacklist” within the postgresDB. Inserting a new factId into the table
triggers a notification that is sent to the FactCast and updates the internal representations of the running Factcast
Servers to make sure that changes take immediate effect.
In order to document why the facts have been blacklisted, you can use the reason column (of type text). It will
not be use for anything else, so there are no expectations on the content.
The filesystem blacklist
As an alternative you can provide a list of blocked fact-ids in JSON format from a file located in the classpath or the
filesystem. Consult the properties page on how to set this up.
Keep in mind that this feature has very limited use-cases and in both implementations, the list of IDs is kept in memory for
performance reasons, so please keep it very, very short.
7 - Tail Indexing
The tail index is a performance optimization for FactCast which speeds up queries
against the end (the tail) of the fact log.
Background
Global Index
FactCast uses a Postgres database for its persistence. Facts live in a single database table
called fact which is referred to as the fact log. To speed up access to the fact log,
a global index is used.
However, as the fact log is constantly growing, so is the index.
With the global index alone, query performance decreases over time.
Subscription Phases
In general, subscriptions may consist of two possible phases:
- Catching up with past events, that have not yet been processed by the consumer
- Checking for new events by querying the tail of the fact log
Note
- Non-follow subscriptions only consist of phase one (they complete after catching up with the past)
- Follow subscriptions consist of phase one and two
- Ephemeral subscriptions, only consist of phase two (ignore the past and just listen to facts as they are published)
Tail Indexes
A tail index supports the regular “are there new events (since X)?” queries by creating additional smaller partial indexes
at the end of the fact log:
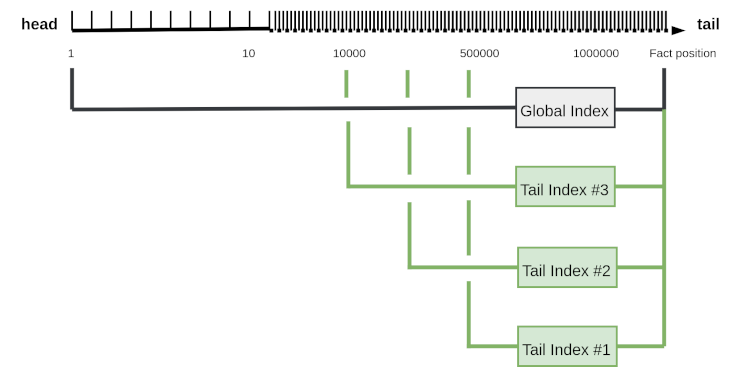
More precisely, FactCast maintains a certain number of rolling partial (tail) indexes.
When asked to query facts from the end of the fact log,
the Postgres database now has the option to use the smaller tail index, which (as many queries are concerned with the tail of the fact log) is likely to be cached in memory.
Tail index rotation is configurable and described in the configuration properties.
Index Maintenance Trade-Off
Introducing a new index does not come for free. When new facts are INSERTed, the Postgres database needs to maintain
the indexes of the fact log. Hence, the higher the number of indexes, the slower the INSERT performance.
See the recommendations of the configuration section for sensible values
on the number of tail index generations.
If you encounter performance issues, see the Postgres documentation for further advice.
Fast-Forward
The Fast-Forward feature further improves the effectiveness of tail indexes by pushing a client’s fact stream position to the end of the fact stream where possible.
Based on the fact log diagram above, here is an example of how a regular check for new events without Fast-Forward would work:
sequenceDiagram
FactCast Client->>FactCast Server: Are there new facts after position 10?
Note right of FactCast Server: look for new facts <br/> via the Global Index
FactCast Server->>FactCast Client: No, nothing new
Note over FactCast Client,FactCast Server: After some time...
FactCast Client->>FactCast Server: Are there new facts after position 10?
Note right of FactCast Server: look for new facts <br/> via the Global Index
FactCast Server->>FactCast Client: ...
The client asks the server for new events after its current fact stream position, “10” using a non-follow subscription. Since
this position is not within the bounds of the tail of the fact log anymore, the FactCast database has to scan the global index
to check for new facts, which will take some time.
As there are no recent events, the fact stream position stays at where it is, and after a while,
the same expensive query via the global index might be repeated, given that there were no new facts of interest to this particular subscription published.
With Fast-Forward however, the situation is different:
sequenceDiagram
FactCast Client->>FactCast Server: Are there new facts after position 10?
Note right of FactCast Server: look for new facts via <br/> the Global Index
FactCast Server->>FactCast Client: No, nothing new. Your new fact stream position is 500000
Note over FactCast Client,FactCast Server: After some time...
FactCast Client->>FactCast Server: Are there new facts after position 500000?
Note right of FactCast Server: look for new facts <br/> likely to be found in a tail index
FactCast Server->>FactCast Client: ...
Here, the client still asks the server for new events after its current position “10”. Again,
the FactCast database has to use the global index. However, besides informing that no new events were found,
the client is fast-forwarded to position “500000” in the fact stream, which is the current beginning of the latest tail index.
Looking at the diagram of the fact log above, we see that position
“500000” is the beginning of the most recent tail index #1. On its next call, the client uses this position as the start of the fact stream.
Since this position is covered by a tail index, FactCast can scan much quicker for new events than before.
Fast-Forward can be imagined like a magnet on the right hand, tail side of the fast stream: Whenever possible,
FactCast tries to drag clients from a behind position to the tail of the fact stream in order to avoid scanning the same index again, once the consumer comes back asking for “Any news?”.
Note
- To omit unnecessary writes of the fact stream position on the client-side, FactCast always offers the beginning of
the currently latest tail index to the client.
- Fast-Forward is a client- and server-side feature of FactCast 0.4.0 onward. However, older clients remain compatible
with a newer FactCast server as the additional Fast-Forward notification is not sent.